Introduction
As our project grows and we begin to bring on more talent to contribute in an open-source manner, we felt it necessary to give a deep dive into the history of L3 Atom, as well as where we’re at currently and what plans we have for the future. This video outlines the core features of L3 Atom and goes over, in detail, how the current MVP functions.
Resources and Guide
Our data can be accessed via websocket by connecting to the following endpoint:
ws://194.233.73.248:30205/
The following code is a sample that subscribes to one of our raw endpoints and immediately begins printing the data it receives.
import asyncio
import websockets
import json # For the json.dumps functionendpoint = "ws://194.233.73.248:30205/"async def connect():
async with websockets.connect(endpoint) as websocket:
print("Connected")# Subscribing to Okex raw feed
request = {"op": "subscribe", "exchange": "okex", "feed": "raw"}
request_json = json.dumps(request).encode('utf-8')
await websocket.send(request_json)
print("Subscribed")# Printing out data
async for message in websocket:
print(json.loads(message))if __name__ == "__main__":
asyncio.run(connect())
You can find our full documentation at https://gda-fund.gitbook.io/l3atom-v2-docs/, which includes a quick-start guide and a complete reference for our API.
You can contact us via jay.taylor@gda.fund if you have any questions/concerns/feedback.
Transcript
What is L3 Atom?
L3 Atom is an open-source universal data collector, normaliser, and disseminator for Web3. It collects raw data from a variety of different sources in the crypto sphere and generates useful insights and indicators that high-frequency and algorithmic traders can use to develop strategies and algorithms. It also has use cases in academia, serving as a one-stop-shop for academics to source data, both on-chain and off-chain, for studying the dynamics of the blockchain and cryptocurrency markets. Currently, the project collects data from 13 exchange APIs, and is sourcing data from Ethereum directly.

Cryptocurrency has an issue with the availability of its data. Simply getting raw data from the blockchain itself typically requires direct access to a node of that chain, which is an inherently exclusionary system that requires an initial investment for granular and real-time data, whether that be running a node yourself, renting a node from a service like Infura or Alchemy, or using an expensive pre-existing API like Glassnode. Off-chain data faces a similar issue — while exchanges have public endpoints that can give real-time, granular data, the informational asymmetry between hedge funds and the average shitcoin investor regarding technical analysis creates a massive disadvantage for the little guy. By creating a data lake that is completely free, open-source, and robust, we aim to solve these issues by giving data to the people and providing them with the tools to compete with hedge funds and those who can afford to pay other companies to do all the hard work for them.

History
The idea for L3 Atom began in 2020, when we were looking around for web3 data providers that gave us granular market data. We noticed that all the providers out there charged insanely high prices — up to $100,000 per month per license, just for market data. We viewed this as a serious issue — restricting web3 data to only those who could afford to pay massive fees for it meant that the necessary information to understand the blockchain and its various dynamics was exclusive and fundamentally against the principles of cryptocurrency in the first place. In October of 2021 we came up with the idea for a data lake that was available to all users and didn’t have any restrictions. Around December of 2021, we decided to make everything completely open source and transparent.
Roadmap
V1
In February of 2022 we launched the first version of the MVP for L3 Atom. This version was small in scale and function, but was a necessary first step in the project’s journey. It covered just 11 centralized exchanges, and was hosted on a single VPS we rented for a few dollars every month. It allowed for a raw feed from each exchange, and an aggregated normalised feed that combined the data from all exchanges into a single stream.
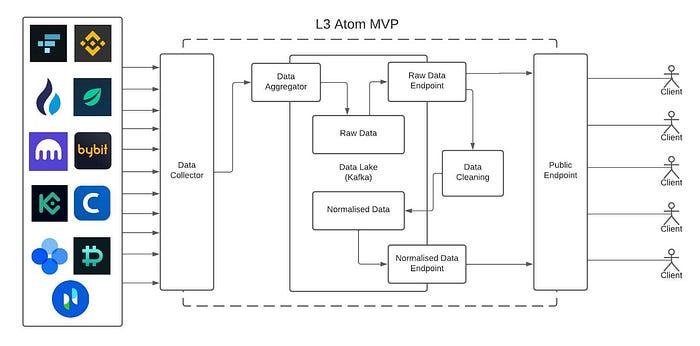
V2
The second version of the MVP was launched in May, and boasts a much more scalable and maintainable codebase and infrastructure. We migrated to AWS and dockerised our services into containers, which makes the entire project portable and trivial to migrate in the future. We also added more topics, including the ability to get normalised data for each individual exchange seperately, as well as on-chain data from Uniswap, taken directly from an Ethereum node.
Scale
The scale version of the MVP will boast far larger sources of data, and will also include useful indicators and metrics that users can incorporate in their trading bots and strategies. Currently, L3 Atom has a focus on raw market data, but our plans for the future involve robust and comprehensive metrics and indicators that can help users understand cryptocurrency markets and the blockchain. We will also have far more data sources, supporting hundreds of exchanges and dozens of chains.
V2 Architecture
Coverage
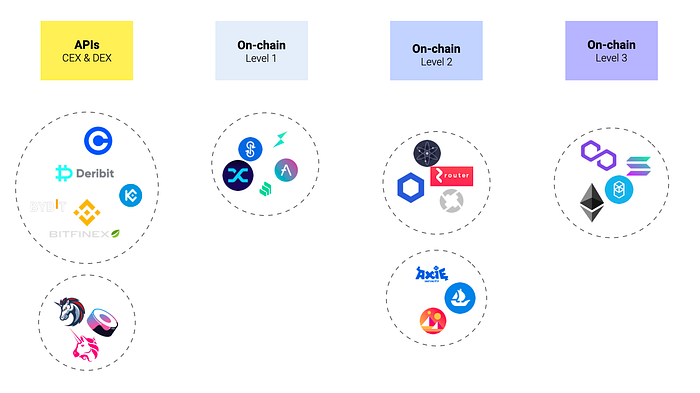
The current MVP covers 11 centralised exchanges and 2.5 decentralised exchanges. I say .5 because we include Uniswap, but don’t have full granularity of that data at the present moment. That’s mainly due to how we collect data from Uniswap, which leverages their smart contracts directly. If you know how Uniswap works, then you can understand why this makes data collection trickier than usual — Uniswap doesn’t have an order book, which makes it unique from the other 13 exchanges we collect data from. The other 2 DEXes have websocket endpoints which makes collection trivial.

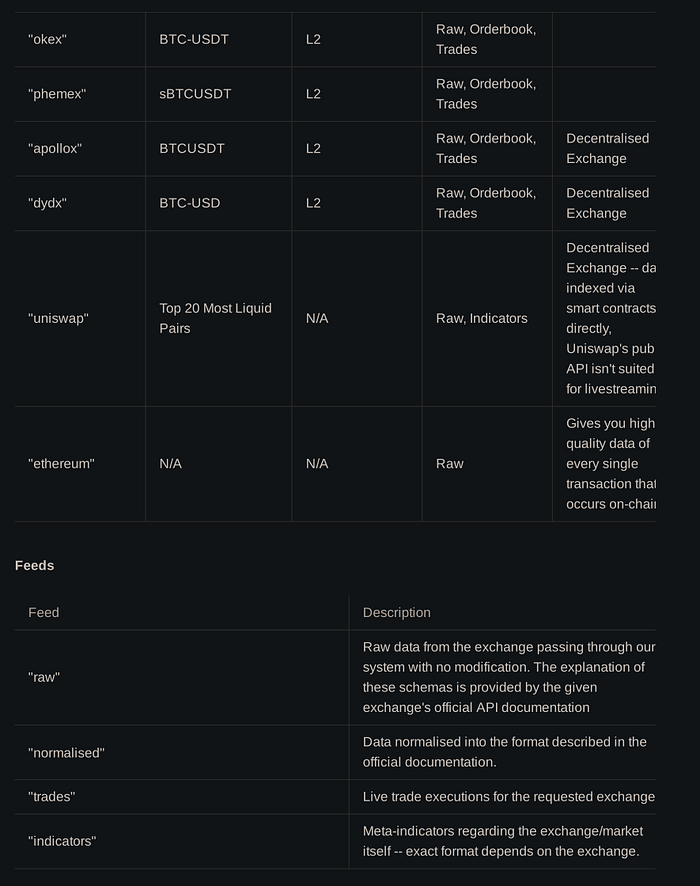
Off-Chain Data Collection
Our off-chain data collection leverages existing public API endpoints provided by the various exchanges. These APIs give us granular order book events, as well as updates whenever matches occur. For most, as soon as we subscribe to the websocket endpoint, we’re sent a snapshot of the current order book state. For some exchanges, however, we have to make a separate REST API call to get that initial state. Afterwards, we have to track sequence numbers to ensure that we don’t double up on information that may have been sent out of order.

async def main():
raw_producer = KafkaProducer("binance-raw")
normalised_producer = KafkaProducer("binance-normalised")
trades_producer = KafkaProducer("binance-trades")
symbols = get_symbols('binance')
await connect(book_url, handle_binance, raw_producer,
normalised_producer, trades_producer, symbols,
True)async def handle_binance(ws, raw_producer, normalised_producer, trades_producer, symbols, is_book):
normalise = NormaliseBinance().normalise
for symbol in symbols:
subscribe_message = {
"method": "SUBSCRIBE",
"params": [
symbol.lower() + "@trade",
symbol.lower() + "@depth@100ms"
],
"id": 1
}
await ws.send(json.dumps(subscribe_message))
snapshot = await get_snapshot(snapshot_url + "?symbol=" +
symbol.upper() +
"&limit=5000")
await produce_message(snapshot, raw_producer,
normalised_producer, trades_producer,
normalise)
await produce_messages(ws, raw_producer, normalised_producer,
trades_producer, normalise)
On-Chain Data Collection
As of making this video, our on-chain data collection is limited, but the existing solutions can serve as a foundation for how future chains and protocols will be implemented. We get our on-chain data directly from nodes, operated by third party infrastructure providers who handle the setup and maintenance for us. We chose to go this route for a few reasons:
- Handling the nodes ourselves would raise transparency issues; how could the public be sure we weren’t just tampering with the data ourselves?
- Operating our own nodes are a logistical nightmare — we’re a small team and don’t have the resources to manage an entire server that would most likely have to handle massive throughput
- Companies like Infura and Alchemy have an already-existing reputation as de facto sources for blockchain interaction
Using the Websocket endpoints for these providers, we can track whenever a new block comes in, currently just on Ethereum. Once that happens, we call smart contract functions and query event filters to get new updates in relevant data points. For Uniswap in particular, we use their subgraph API to obtain meta-indicators regarding the platform as a whole. Some Ethereum DEXes offer public websocket endpoints, and so we ingest data for those sources in almost the exact same way as the off-chain exchanges.
async def main():
raw_producer = KafkaProducer("uniswap-raw")
indicators_producer = KafkaProducer("uniswap-indicators")
async with websockets.connect(conf["INFURA_WS_ENDPOINT"]) as ws:
flag = asyncio.Event()
logging.info("Connected to websocket")
await ws.send(json.dumps({"jsonrpc": "2.0", "id": 1, "method": "eth_subscribe", "params": ["newHeads"]}))
await ws.recv()
logging.info("Subscribed to websocket")
pairs = []
response = json.load(open("./src/schemas/indicator_response_template.json"))
get_top_100_pairs(pairs, web3)
await create_tasks(pairs, response, flag, raw_producer)
logging.info("Tasks created")
asyncio.create_task(update_stats(response))
logging.info("Global stats collected")
# From the factory, we want to know when a new pool is created
factory_event_filter = await factory_contract.events.PairCreated.createFilter(fromBlock='latest')
flag.set()
while True:
new_block = await ws.recv()
new_block = json.loads(new_block)
flag.clear()
response["block_number"] = int(new_block["params"]["result"]["number"], 16)
response["timestamp"] = int(new_block["params"]["result"]["timestamp"], 16)
logging.info("Received new block: %d" % response["block_number"])
new_pairs = await update_pairs(pairs, factory_event_filter, response)
indicators_producer.produce(key=str(response["block_number"]), msg=json.dumps(response).encode())
await create_tasks(new_pairs, response, flag, raw_producer)
refresh_response(response)
flag.set()Normalisation
We’ve constructed schemas and tables for a variety of different data forms, and so this stage in the process is primarily concerned with transforming and mutating the raw data we’ve collected into normalised forms that can be used for metric/indicator development. For off-chain sources, this mainly requires simple mutations and calculations to get the data in the format that we want. We leverage the fact that most exchange APIs are similar in the data they send out, although the exact normalisation algorithms and forms tend to naturally differ. On-chain normalisation is trickier due to the inherent differences in smart contracts. Each protocol implements their contracts differently, and when protocols operate on fundamentally unique technology, finding a common ground between them to normalise can be a challenge. Normalising on-chain data typically requires making function calls to the Ethereum chain to get additional metadata (wallet balances, token addresses, e.t.c.) and mutating the raw data we collect into a normalised format.
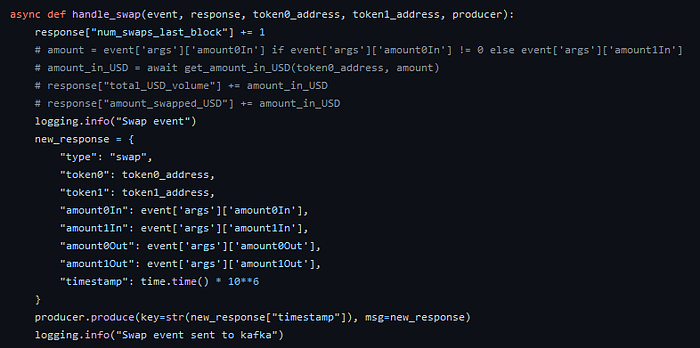
async def handle_swap(event, response, token0_address, token1_address, producer):
response["num_swaps_last_block"] += 1
# amount = event['args']['amount0In'] if event['args']['amount0In'] != 0 else event['args']['amount1In']
# amount_in_USD = await get_amount_in_USD(token0_address, amount)
# response["total_USD_volume"] += amount_in_USD
# response["amount_swapped_USD"] += amount_in_USD
logging.info("Swap event")
new_response = {
"type": "swap",
"token0": token0_address,
"token1": token1_address,
"amount0In": event['args']['amount0In'],
"amount1In": event['args']['amount1In'],
"amount0Out": event['args']['amount0Out'],
"amount1Out": event['args']['amount1Out'],
"timestamp": time.time() * 10**6
}
producer.produce(key=str(new_response["timestamp"]), msg=new_response)
logging.info("Swap event sent to kafka")Data Pipeline
We use Apache Kafka to communicate our data between processes and nodes. Kafka was chosen as it is an efficient and simple-to-use pub/sub service that provides us with the reliability and throughput we were looking for. In the future, however, we wish to migrate to Redis, an extremely high-performant alternative that can sit on AWS elasticache, where we host our other compute nodes. When we process a new entry of raw data, we publish different versions of it to different topics in Kafka. For off-chain data, for example, each exchange has a “normalised”, “raw”, and “trades” topic. This ensures that these different feeds are separated, and so allows for users to choose which specific feed they want to subscribe to.
Data Dissemination
Our websocket server is an adapter layer directly connected to our Apache Kafka cluster. It is the access point for receiving real time data from our service. Using our endpoint, any application or script which supports websocket connections can connect, send, and receive from L3 Atom. The server continuously pulls data from Kafka topics in real time and publishes the data through websocket connection to any subscribers. The server is optimised through high performance libraries such as websockets and uvloop, giving greater connection handling capacity per machine. In the near future, we are load balancing the server and scaling the number of connection handling instances using AWS, giving us even greater capacity and performance.
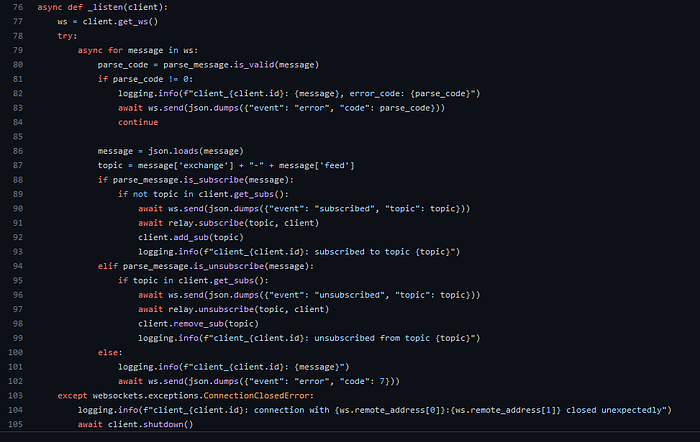
async def _listen(client):
ws = client.get_ws()
try:
async for message in ws:
parse_code = parse_message.is_valid(message)
if parse_code != 0:
logging.info(f"client_{client.id}: {message}, error_code: {parse_code}")
await ws.send(json.dumps({"event": "error", "code": parse_code}))
continue
message = json.loads(message)
topic = message['exchange'] + "-" + message['feed']
if parse_message.is_subscribe(message):
if not topic in client.get_subs():
await ws.send(json.dumps({"event": "subscribed", "topic": topic}))
await relay.subscribe(topic, client)
client.add_sub(topic)
logging.info(f"client_{client.id}: subscribed to topic {topic}")
elif parse_message.is_unsubscribe(message):
if topic in client.get_subs():
await ws.send(json.dumps({"event": "unsubscribed", "topic": topic}))
await relay.unsubscribe(topic, client)
client.remove_sub(topic)
logging.info(f"client_{client.id}: unsubscribed from topic {topic}")
else:
logging.info(f"client_{client.id}: {message}")
await ws.send(json.dumps({"event": "error", "code": 7}))
except websockets.exceptions.ConnectionClosedError:
logging.info(f"client_{client.id}: connection with {ws.remote_address[0]}:{ws.remote_address[1]} closed unexpectedly")
await client.shutdown()Historical Storage
The Historical Storage services run at the same layer of the websocket server, collecting data from our Kafka topics and converting them into a csv format. It holds data from the topics in memory until the temporary data structure reaches a certain number of rows or size, then puts the object into AWS S3 as a csv file. The file is timestamped and continuous, so data coming from Kafka is losslessly archived on the cloud for use in the future. At the moment, we archive orderbook and trades data from four of our centralised venues and one decentralised venue. After we scale up our computation, we will replicate the archiver service for every single topic we have available.
Currently, there is no way to query the csv objects on AWS S3. The csv files will be used to create an initial data supply after we migrate to a more suitable data warehousing or querying service, such as AWS Redshift or AWS Timestream. However, we are happy to provide sample csv data upon request.
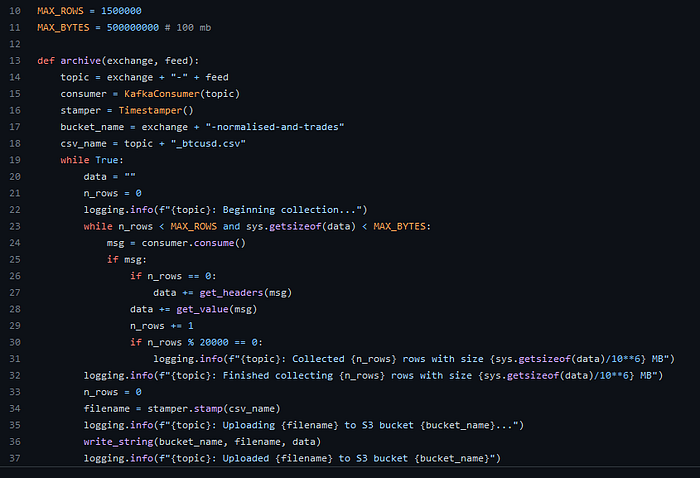
MAX_ROWS = 1500000
MAX_BYTES = 500000000 # 100 mbdef archive(exchange, feed):
topic = exchange + "-" + feed
consumer = KafkaConsumer(topic)
stamper = Timestamper()
bucket_name = exchange + "-normalised-and-trades"
csv_name = topic + "_btcusd.csv"
while True:
data = ""
n_rows = 0
logging.info(f"{topic}: Beginning collection...")
while n_rows < MAX_ROWS and sys.getsizeof(data) < MAX_BYTES:
msg = consumer.consume()
if msg:
if n_rows == 0:
data += get_headers(msg)
data += get_value(msg)
n_rows += 1
if n_rows % 20000 == 0:
logging.info(f"{topic}: Collected {n_rows} rows with size {sys.getsizeof(data)/10**6} MB")
logging.info(f"{topic}: Finished collecting {n_rows} rows with size {sys.getsizeof(data)/10**6} MB")
n_rows = 0
filename = stamper.stamp(csv_name)
logging.info(f"{topic}: Uploading {filename} to S3 bucket {bucket_name}...")
write_string(bucket_name, filename, data)
logging.info(f"{topic}: Uploaded {filename} to S3 bucket {bucket_name}")
Wrap Up
How to Access
Our current data feeds can be accessed via a websocket endpoint. A link to our official documentation which outlines how to subscribe to this endpoint and start receiving data is in the description. It also includes a quick-start guide which you can run straight away to start receiving data.
FAQs
How is this all being payed for if it’s free?
L3 Atom is a small component of a bigger project that is providing a comprehensive toolkit for financial engineers to create trading strategies and bots. That platform will be our main source of revenue, but besides that, we have already secured large donations from trusted third-party sources and protocols. Our aim for this project is to completely bootstrap it. That means no VCs or external investors. It would be incredibly easy for us to charge a premium for the data we’re providing, but that’s not at all the route we want to go down.
Which ticker symbols can we access for each supported exchange?
Each exchange only supports one trading pair by default — one of BTCUSD, BTCUSDT, or one of the derivatives of those pairs. The reasoning behind this is that each symbol requires its own microservice — consider doing that for every exchange and with multiple feeds, and you can see how the computation required can scale up really quickly. It was a tough decision, but for the MVP, we decided to focus on the most common tickers to begin with.
Are we allowed to fork and extend your implementation?
For sure, the project is completely open source. We’ll post links to our GitHub in the description.
Conclusion
That was a brief overview of Project L3 Atom, its history, where it’s at, and what we have planned for the future. If you have any questions, feel free to shoot them at us via email. We’ll paste all our contact details in the description of this video. Thanks for watching!
